
对于 AI 烧钱,业内流传着多样令东说念主缄默尴尬的数字。xAI 花了最初 10 亿好意思元建起 Colossus 超算集群;OpenAI 的月度算力账票据称高达数亿好意思元;Anthropic 最近几轮融资拿到的钱,在公众眼里险些依然和「GPU 时数」平直画上了等号。
内行谈的,险些都是算力。GPU 成了估量一家 AI 公司实力的通用货币,亦然每一篇融资报说念里最显眼的阿谁数字。
但最近,我听了一期 Latent Space 播客,采访对象是 xAI 前沟通员 Ethan He——Ethan 在 2025 年中加入 xAI 时,面对的是一个莫得基础步骤、没迥殊据、莫得现成模子的白纸情景,然后用三个月时期和一支小团队,从零搭建出了 Grok Imagine 视频生成系统,作念到了那时业内的一活水准。
在聊到大范围视频模子的老师本钱时,他说了一组数字,让我俄顷理解到,这个行业可能一直在算错了账。
「光是存储这些视频和特征数据,每个月就要几百万好意思元——这还没算算力本钱。」
01
账单上的荫藏本钱
从零到一,驱动老师一个视频大模子,需要花几许钱?先假定你的团队有矿,GPU 算力歪邪用。即便如斯,你可能依然低估了这件事的巨量本钱。
假定你要老师一个宇宙级的视频生成模子,去网上爬取了 10 亿条视频,每条平均 5MB——这依然是十分保守的臆度了。光这一项,你就需要 5PB(拍字节)的存储空间。按照 AWS S3 的订价,5PB 圭臬存储,每个月简短 10 万好意思元。
但这还仅仅原始视频。
在老师视频模子之前,业界通行的作念法是先用 VAE(变分自编码器)把视频压缩成「潜在空间」的特征向量——因为一段视频张开成像素,可能有几十亿个 token,任何 Transformer 都处置不了,必须先压缩成模子能意会的结合向量。
问题是,这份压缩后的特征数据,体积和原始视频十分,相似需要恒久存储,随时备用。
两项重叠,数十 PB,每月存储费就最初 20 万好意思元。
然后是最突如其来的那一项:数据收支费(egress/ingress)。
Ethan 说,从互联网下载 10 亿条视频的带宽用度,在 AWS 上比存储这些视频还贵。每次老师,数据都要从存储层拉到谋略层跑一遍。视频模子的老师不像话语模子那样训完就完毕——要迭代,要调参,要测试不同的数据配比,澳门威尼斯官方网站每一次实验都意味着把全量数据再过一遍。实验跑得越多,这笔钱就乘以相应的倍数。
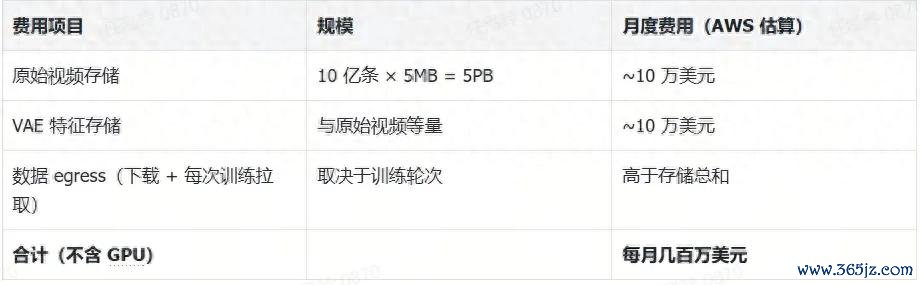
综划算下来,Ethan 的估算是,光是数据这一块,每个月就要几百万好意思元。GPU 的用度,还没驱动计入。
这笔账大发官方网站手机app,我从来没见哪篇 AI 行业报说念细算过。
02
扛不住的带宽费
那像 xAI 这么自建 Colossus 数据中心的公司,是不是在存储和带宽上省了一大笔钱?
Ethan 的回应很平直:「诚然,省了许多。」
这句话背后,藏着视频 AI 行业一个不太被沟通的结构性玄妙。
诳言语模子的老师数据是文本,体积相对轻量,况兼老师完成之后,原始数据基本就完成了职责——你不需要反复拉取全量语料来作念推理或微调。但视频数据皆备不同:体积是文本的几个数目级,况兼每一次老师实验都要把全量数据齐全过一遍。
迭代速率越快,数据搬运的本钱就越高;而 Ethan 反复强调,迭代速率,恰正是视频模子研发中最要道的变量。
这就酿成了一个相互咬合的困局:你需要快速迭代来普及模子质料,但快速迭代意味着时常搬运数据,而时常搬运数据在公有云上的账单会把你压垮。
Ethan 本东说念主的轨迹等于一个注脚。他在 NVIDIA 参与构建了 Cosmos 宇宙模子,作念着作念着理解到,大发官方网站手机app视频模子存在和话语模子近似的「范围定律」,还有很大的普及空间。他那时面对的遴荐,名义看是「我需要更多 GPU」,但相似要道的一句话他没明说——他需要一个无谓按 AWS 账单算钱的方位,来存放和搬运数据。这亦然他去 xAI 的根柢原因之一,而 Colossus 给了他阿谁环境。
对于莫得自建基础步骤的团队来说,这笔账是如何算的?每个月几百万好意思元的数据本钱,重叠在 GPU 算力之上,意味着哪怕你有一流的算法团队,哪怕你募到了实足的资金,只消你还在用公有云,你等于在用一个无底洞的账单跟敌手的自建机房竞走。
2026FIFA世界杯赛事官网入口这说念门槛,不是一家有优秀算法的创业公司能靠「本领取胜」跨昔日的。
03
视频模子的护城河不是模子
这让我念念起一个趣味趣味趣味趣味的对比。
在诳言语模子范围,「开源 vs 闭源」的竞争打得十分热烈,Llama 系列的出现让许多小团队也能在话语模子上打出有竞争力的家具,致使逼着 OpenAI 和 Anthropic 不休压低 API 价钱。但在视频生成范围,咱们看到的方法判然不同:能不绝作念出顶尖视频模子的,基本只消 Sora、Veo、可灵这些背靠巨量资源的团队,莫得一家是靠开源社区在车库里跑出来的。
许多东说念主把这归结为「数据和算力的差距」。这诚然没错,但 Ethan 揭示的这组数字告诉咱们,问题比这更深:视频 AI 的基础步骤本钱,从一驱动就把竞争的门槛,锁死在了小数数玩家的高度上。
这和半导体行业的逻辑有几分相似。台积电之是以难以撼动,不单因为它们有更好的瞎想,更因为一座新晶圆厂需要几百亿好意思元的前期进入,这说念门槛自己等于最佳的护城河。视频 AI 的护城河,等于那数十 PB 的数据基础步骤和每月革新产生的带宽账单。
Ethan 在播客里还补充了一个更深的践诺:视频模子的「智能」,大部分其实来自背后的话语模子,而不是视频扩散模子自己。
视频扩散模子相对「愚钝」,它只会按照翰墨描写照单全收地生成画面,描写写「一只猫」,它就生成一只猫,站在纯白配景前,保残守缺——因为你莫得告诉它配景是什么、猫在作念什么。
果然意会用户意图、把「一只猫」扩写成一段精良的镜头话语描写的,是背后阿谁作念「领导词重写」的大型话语模子。Ethan 说,在 Cosmos 时期,他也曾用一个「抖擞的羊」作念测试:不流程领导词重写,生成出来的画面极其 CGI、毫无质感;加上重写之后,恶果判若云泥——而统统视频扩散模子自己,并莫得发生任何改变。
这意味着,决定一家公司在视频 AI 范围能走多远的,不仅仅视频模子的参数范围,而是能否同期撑起话语模子和视频模子这两套基础步骤,并让它们灵验协同。
这是一场拼空洞膂力的竞赛。
04
下一个战场,早就被划好了
诚然,行业也在摸索出息。
领导词重写的 Agent 化、让话语模子像「指挥官」一样转换多个视频生成用具、用 FFmpeg 这类传统软件处置中间门径——这些方针的共同逻辑是,把「话语模子的推理本钱」和「视频扩散模子的生成本钱」分层谋略,让每一次视频生成的调用愈加精确,减少无效的谋略和数据搬运。
Ethan 对「视频 Agent」的走向十分确定。他预计本年年底将出现一个拐点——当 Agent 生成的视频质料省略褂讪达到「可投放生意告白」的水准,企业才会果然舒心为之买单,举座的本钱结构也会随之演变。
但有一丝不会变:谁掌执了数据的存储和流转,谁就掌执了这场游戏的来源。
在 AI 这个赛说念上,「果然的壁垒」每隔一段时期就会交替一次。先是参数目,然后是老师数据范围,然后是对皆本领,然后是推理服从。当今,视频 AI 正在揭示下统统壁垒——不是某种微妙的算法冲破,而是一份冷飕飕的基础步骤账单。
这笔账,从一驱动就没贪图让统统东说念主都算得起。